OR-Tools:从入门到系统构建
前言
在实际工程中,很多问题并不是“算一个数”,而是“在大量候选方案中,选出一组满足规则、同时尽量优”的解。
我在王俊刚老师的启发下,正在着手做一个自动组卷系统:
- 每道题只有「选 / 不选」两种状态(0/1 变量)
- 需要满足总分、题型、标签等硬约束
- 同时让整张试卷的难度尽量接近目标值(软约束 / 优化目标)
这类问题天然属于 约束满足问题(CSP)/ 约束优化问题(COP),而 OR-Tools 的 CP-SAT 正好非常合适。
我将结合自己的开发各阶段,完整记录一次 从建模 → 实现 → 性能瓶颈 → 优化思路 的过程。
这个项目将长期维护,并可能拓展到其他领域开发,比如数据库、网页设计等。
我自己也在Obsidian上绘制思维导图,来记录主干思路
一、问题抽象:这是一个什么模型?
自动组卷系统,就是在大量题库中,按照给定的要求,合理地选取题目,来组成一张完整的卷子。
所以,我们可以注意到,这个系统,其实不讲究最优解,甚至反而强调随机性和可复现性。
那么,拿到一个题库,首先要进行一个建模
1. 决策变量
对题库中每一道题 $q_i$,定义一个 0/1 变量:
- (x_i = 1):选这道题
- (x_i = 0):不选
单个tag的题目规模可以达到 200 ~ 10000 题,综合所有tag更是近乎十万级别
这是后期优化的一个重点领域,是此类系统的必经之路
2. 约束
这是“必须满足”的条件,例如:
- 总分 = 100 分
- 至少包含 1 道证明题 -(可选)某些标签至少出现若干次
这些条件一旦违反,解就不可行,在模型中就会被“剪枝”
3. 优化目标
目标不是“有没有解”,而是:
在满足所有约束的前提下,让试卷难度尽量接近给定目标
这就把问题从 CSP 推进到了 COP(Constraint Optimization Problem)。
那么,我们就顺水行舟,先来学习一下CSP的相关知识叭
二、概念梳理:CSP
一组变量,每个变量有自己的值
当每个变量的赋值同时满足所有关于变量的约束时,问题就得到了解决
这类问题就叫做约束满足问题(CSP),全称Constraint Satisfaction Problem
资料引用自人工智能第六章——约束满足问题(CSP)
1. 线性优化问题长什么样?
在优化领域,线性优化(或线性规划)是最古老和最广泛使用的问题之一,其中其目标函数和约束可以写成线性表达式
在一下约束条件下最大化 $3x + y$:
\[0 \le x \le 1\] \[0 \le y \le 2\] \[x + y \le 2\]在这个例子里目标函数是 $3x + y$。目标函数和约束都是由线性表达式给出的,这使得这是一个线性问题。
2. 求解问题的主要步骤
对于每种编程语言,建立和解决问题的基本步骤都是相同的:
- 导入必需的依赖库 (OR-Tools)
- 声明求解器
- 创建变量
- 定义约束
- 定义目标函数
- 调用求解器并显示结果
资料引用自OR-Tools入门教程
3. 使用CSP的优势
CSP的求解比状态空间搜索要快很多,因为CSP求解会利用剪枝,去快速去除大部分搜索空间。一旦发现某部分状态赋值不是解,或者某个变量违反了约束,就会立刻抛弃。
CSP可以通过数学上的损失函数建模,并取能够逼近最小化损失函数的变量赋值。这种“偏好约束”我们称为约束优化问题 COP 。
注:线性规划也有此类优化问题
这里有一个典型的优化问题:
假设一家运输公司使用卡车车队向客户运送包裹。每天,该公司必须将包裹分配给卡车,然后为每辆卡车选择运送包裹的路线。每一个包裹和路线的分配都一个成本,基于卡车的总行驶距离或者其他因素。问题是选择成本最低的包裹和线路分配方案。
与所有优化问题一样,这个问题包含以下元素:
- 优化目标:
- 为了建立一个优化问题,需要定义一个目标函数来计算解决方案的优化数值。在前面的例子中,目标函数将计算任意分配包裹和路线方案的总成本。
- 最优解是目标函数最佳的解。(最佳可以是最大值,也可以是最小值)
- 约束:
- 根据问题的具体要求,限制可能解的集合。例如,如果运输公司不能分配包裹给超过卡车载重,这将对解决方案施加约束。
- 可行解:
- 满足问题的所有给定约束条件,而不一定是最优解。
求解优化问题的第一步是确定目标和约束条件。
资料引用自OR-Tools入门教程
知道了这些基本知识,就可以开始尝试用Python进行建模和求解了
三、两种难度代偿函数建模
这是整个系统的核心设计。它的根本目的是使得选出的题目的难度(或者其他参数)尽量贴近给出的目标值
比如:设定难度的目标是0.5,然后数据库里的题目难度从0.1-0.9不等分布(这个分布我们后续会讨论)
我们可以用两种方法来建立这个代偿函数:整体上和局部上
1. 整体代偿函数(Global Deviation)
思想:
- 只关心整体平均难度
- 允许「难题 + 易题」在整体上相互抵消
- 这是一个“宏观对齐”的 L1 目标,只控制平均难度,不控制单题是否接近目标
建模方式:
- 定义总难度:( \sum x_i \cdot d_i )
- 定义目标总难度:( \text{target} \times \text{题目数} )
- 最小化二者的绝对偏差
特点:
- 搜索空间大
- 自由度高
- 在大规模数据下更容易退化(例如全选 0.7 难度+0.2难度)
# =========================
# 目标函数:最小化整体代偿函数
# =========================
def minimize_total_diff_deviation(model, vars_, questions, target, num_q):
# num_q 是期望选题数量
total_diff = model.NewIntVar(0, 10**7, "total_diff") # 定义变量:所选题目的总难度和
# 对所选题目的难度求和,并赋值到total_diff变量
model.Add(
total_diff == sum(
vars_[f"q_{q['id']}"] * int(q['difficulty'] * 100)
for q in questions
)
)
target_sum = model.NewIntVar(0, 10**7, "target_sum") # 定义变量:理想总难度
# 理想总难度 = 单题目标难度 × 题目数量。这是常数关系,但用变量表达
model.Add(target_sum == target * num_q)
deviation = model.NewIntVar(0, 10**7, "deviation") # 定义变量:总难度偏差
# 两条合起来表示:deviation ≥ |total_diff − target_sum|
model.Add(total_diff - target_sum <= deviation)
model.Add(target_sum - total_diff <= deviation)
# 最小化总难度与目标总难度的绝对偏差
model.Minimize(deviation)
# 用法:
# minimize_total_diff_deviation(
# prob.model, prob.vars, questions, target_difficulty, num_q
# )
2. 局部代偿函数(Item-wise Deviation)
思想:
- 要求每一道被选中的题都尽量贴近目标难度
- 这是一个基于绝对值(L1)的难度贴合目标函数,只对被选题目计入代价
建模方式:
- 对每道题引入一个偏差变量
- 只有在题目被选中时才产生代价
- 最小化所有偏差之和
特点:
- 约束更强
- 剪枝更激进
- 计算量明显更大
# =========================
# 目标函数:最小化局部代偿函数
# =========================
def minimize_item_diff_deviation(model, vars_, questions, target_diff):
item_devs = []
#对于每个题目单独约束
for q in questions:
qi = vars_[f"q_{q['id']}"] # 取出题目 q 是否被选中的 0/1 决策变量
diff = int(q['difficulty'] * 100) # 将题目难度浮点数定点化(×100),避免浮点运算。
# 为该题创建一个非负整数变量,表示该题对目标函数的偏差贡献
dev = model.NewIntVar(0, 10**6, f"dev_{q['id']}")
# 这两条合起来等价于:dev ≥ |diff − target_diff| × qi
model.Add(dev >= (diff - target_diff) * qi)
model.Add(dev >= (target_diff - diff) * qi)
item_devs.append(dev) # 将该题的偏差变量加入列表
total_dev = model.NewIntVar(0, 10**7, "total_item_dev") # 定义总偏差变量
model.Add(total_dev == sum(item_devs)) # 总偏差等于所有题目偏差之和
# 设置目标:最小化选中题目的总难度偏差
model.Minimize(total_dev)
# 用法:
# minimize_item_diff_deviation(
# prob.model, prob.vars, questions, target_difficulty
# )
这两种模型我都实现了,可以在工程中自由切换。目前来看,大数据量时,整体的时间消耗比局部好太~多~太~多~了,但是题目难度也会退化。所以两个我们都要进行优化
后面我的实现方式是采用用户提供的难度分布曲线来逼近各难度题目数量,具体实现方式是最大余数法进行整数分配
# 若比例总和不为1则归一化
if abs(total_proportion - 1.0) > 1e-6:
for star in proportions:
proportions[star] = proportions[star] / total_proportion
# 定义字段:分别存储“目前暂定的分布(整数)”和“分布比例取整后的余数”
distribution = {}
remaining = {}
for star_name, proportion in proportions.items():
exact_value = proportion * total_number
distribution[star_name] = int(floor(exact_value))
remaining[star_name] = exact_value - distribution[star_name]
diff = total_number - sum(distribution.values())
stars_sorted_by_remainder = sorted(remaining, key=remaining.get, reverse=True)
for i in range(diff):
target_star = stars_sorted_by_remainder[i]
distribution[target_star] += 1
return distribution
三、工程实现:CP-SAT 建模结构
我自己写代码的话,还是会非常喜欢使用面向对象编程,不然一坨shit糊在屏幕上真的让人吃不消…更何况我还有多动症,更难集中注意力了
因此我的整体代码结构是偏“工业风”的封装:
CPSolver:对 CpModel / CpSolver 的轻封装- 约束函数模块化(分数、题型、标签)
- 目标函数单独定义,便于切换实验
核心的话,就是不要把逻辑写死。所谓建模,就是建出来了还要能方便地调用。
我的代码大概如下:
CPSolver类封装:
class CPSolver:
def __init__(self):
self.model = cp_model.CpModel()
self.vars = {}
self.solver = cp_model.CpSolver()
def add_int(self, name, lb, ub):
self.vars[name] = self.model.NewIntVar(lb, ub, name)
return self.vars[name]
def solve(self, time_limit=None):
if time_limit:
self.solver.parameters.max_time_in_seconds = time_limit
start = time.time()
status = self.solver.Solve(self.model)
end = time.time()
output(status, end - start, self.solver, self.vars)
return status
def val(self, name):
return self.solver.Value(self.vars[name])
约束构造:
# =========================
# 约束构造
# =========================
#保证总分100分
def add_score_constraint(model, vars_, questions, total_score=100):
model.Add(
sum(
vars_[f"q_{q['id']}"] * (q['points'] if q['points'] > 0 else 5)
for q in questions
) == total_score
)
#保证包含证明题
def add_proof_constraint(model, vars_, questions, min_count=1):
proof_vars = [
vars_[f"q_{q['id']}"]
for q in questions if q['content_type'] == 'proof'
]
if proof_vars:
model.Add(sum(proof_vars) >= min_count)
#保证包含某标签
def add_tag_constraint(model, vars_, questions, tag, min_count):
tag_vars = [
vars_[f"q_{q['id']}"]
for q in questions if tag in q.get("tags", [])
]
if tag_vars:
model.Add(sum(tag_vars) >= min_count)
用法:(涉及到函数的传参,我就不废话了,自己去网上查)
# 约束:成绩约束、证明题包含约束、标签包含约束(未启用)
add_score_constraint(prob.model, prob.vars, questions)
add_proof_constraint(prob.model, prob.vars, questions)
# add_tag_constraint(prob.model, prob.vars, questions, "矩阵", 5)
主程序构造和相关用法
# =========================
# 主流程
# =========================
def paper_generation_task(file_path, difficulty=0.6):
# 设定难度系数,可以随意调节(理论上)
# 打开题目数据文件
with open(file_path, "r", encoding="utf-8") as f:
questions = json.load(f)
# 难度系数边界保护 正点化难度系数
difficulty = min(max(float(difficulty), 0.3), 0.7) # 如果太高或太低会导致模型退化
target_difficulty = int(difficulty * 100)
# 构造求解器
prob = CPSolver()
# 决策变量 0/1 赋值
for q in questions:
prob.add_int(f"q_{q['id']}", 0, 1)
# 辅助变量:题目数量
num_q = prob.model.NewIntVar(1, len(questions), "num_q")
prob.model.Add(
num_q == sum(prob.vars[f"q_{q['id']}"] for q in questions)
#可以理解为增加了一个约束,要求变量 num_q 严格等于题目数量
)
# 约束 (详见上文)
add_score_constraint(prob.model, prob.vars, questions)
add_proof_constraint(prob.model, prob.vars, questions)
# add_tag_constraint(prob.model, prob.vars, questions, "矩阵", 5)
# 最小化代偿函数(局部代偿函数)
# minimize_item_diff_deviation(
# prob.model, prob.vars, questions, target_difficulty
# )
# 或者使用这个代偿函数(整体代偿函数)
minimize_total_diff_deviation(
prob.model, prob.vars, questions, target_difficulty, num_q
)
# 求解 可以限定时间
status = prob.solve() # time_limit=5
# 汇总输出
if status in (cp_model.OPTIMAL, cp_model.FEASIBLE):
chosen = [
q for q in questions
if prob.val(f"q_{q['id']}") == 1
]
avg_diff = sum(q['difficulty'] for q in chosen) / len(chosen)
print("\n最终题目数:", len(chosen))
print("平均难度:", f"{avg_diff:.3f}")
for q in chosen:
print(f"[{q['content_type']}] id {q['id']} | diff {q['difficulty']} | {q['content']['stem'][:30]}...")
else:
print("无可行解")
四、性能实测
我用随机生成的假数据做了测试:
| 题目数量 | 求最优解时间 |
|---|---|
| 200 | 0.10 s |
| 500 | 0.52 s |
| 1000 | 1.48 s |
| 2000 | 4.9 s |
| 10000 | 95 s |
结论很清楚:
- 对于最小化局部代偿函数,这是一个指数级的搜索问题
- CP-SAT 再强,也不可能“硬刚” 10000 个 0/1 变量(更何况其实我里面还分别定义了新的变量,变量数还要翻个倍)
此外,这样的强约束,如果直接丢给求解器返回最优解,就会理所当然地返回全部都是0.60难度系数的题目,然后花掉95秒时间
于此对比之下,使用整体代偿函数的话,能极大程度降低搜索时间。
- 2000数据量0.9s
- 10000数据量8.6306s
但是!这个难度划分真的是有点过分…
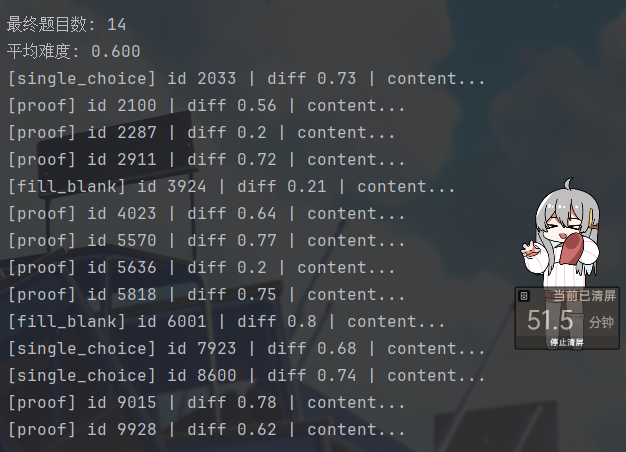
要不全是送分题,要不全是送命题…
也是这个时候,我意识到了这样的问题:
- 我造的数据集实在是太假了,和真实世界的数据有很大的出入,所以会产生“数学上很合理”但是“直观上和草率”的结果
- 要想达到均衡命题,不能完全采取最小化局部代偿函数,而是采用整体代偿函数
- 那么真实的数据,是什么样的呢?
五、除了数据量太大,还有数据太假
思考一下,我们做到的题,它都是什么样的?
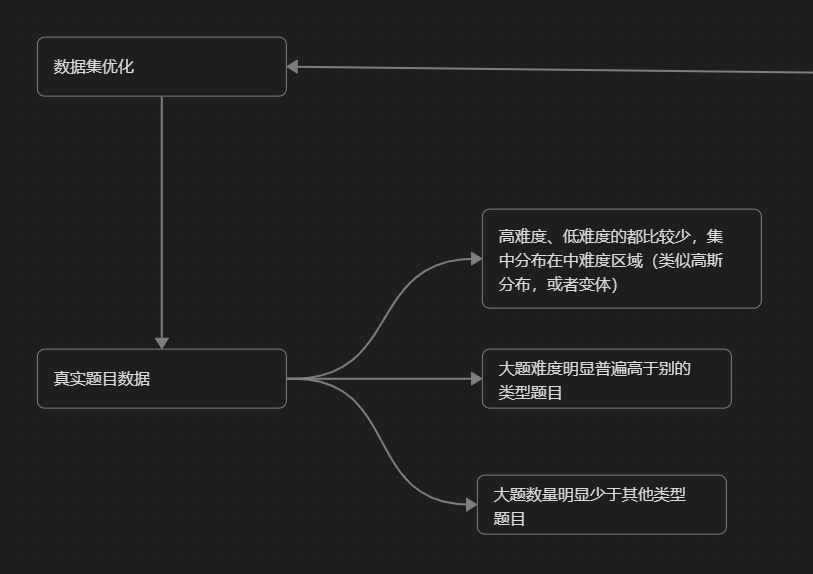
真正的突破点除了 OR-Tools 的函数本身,也在于 数据分布 的合理构造
真实题库并不是均匀随机的:
- 中等难度题目数量最多
- 高难 / 低难题占比较小
- 某些题型、标签高度集中
如果先利用这些统计结构,也许可以在一定程度上压缩搜索空间。
六、核心优化策略和反思
1. 空间换时间:预分层
- 按难度 星级 为步进分桶
- 直接统计每个难度区间的题目数量
- 对“题目密度极高”的区间进行随机下采样
这是在老师的指点下采取的方案。作为毕业的高中生,我从构建这个框架的一开始就理所当然地默认使用0.00-1.00的难度系数划分
实际上,对于这种针对离散数据的线性约束问题,我们的难度系数在操作的时候,本来就要先乘以100来正点化,也就是相当于每道题的难度系数是0-100的整数。如果是这样的话,还不如直接采取更简单的0-6星分级
在使用0-6星分级后,运行时间从原来的8s降到了1s;此外,后期如果添加按照星级比例选题,也会更方便实现
所以,如果对难度设定要求不严格,可以这样来降低运算量
这一步在进入 CP-SAT 之前完成。
2. 题型分治
- 按题型(选择 / 填空 / 证明)分组
- 先在子集上满足强约束
- 再合并进入整体优化
3. 约束本身也是剪枝工具
- 更多结构性约束 ≠ 更慢
- 合理的约束会显著减少搜索树,反而加速搜索过程
这是 CP-SAT 和暴力搜索的本质区别
4. 优秀的题型建模很重要
- 现实中的题目数据库并不是完全随机,而是满足某种分布
- 针对这种情况再来做优化会更高效
5. 不要采用分数约束,采用题量约束
七、Release
经过了很多个版本的迭代,我逐渐构建出来了符合要求的、能够正常运行的版本,所以我想着可以把目前这个状态给发布一下,标志一下一个阶段的结束,便于划分和回溯,于是,我就给这个代码打上了tag,发布在github的release上了
在发布之前,我做了一系列清理,包括把实验代码和过去的题库等数据放到ignore文件夹并清除缓存停止追踪、结构化项目文件夹和适当地模块化拆分等
Release v0.1.0 的明确定位:
明确不包含:
-
UI / Web / API
-
实验性脚本
-
大规模真实题库
八、配置驱动
前面的实现中,所有参数都是写死在代码里的。一方面不好定位和统一管理,另一方面不适合后期调整
比如:
- 总题数
- 各题型数量
- 难度目标
- 难度分布策略
- 文件路径
所以我就开始把这些配置写到config.yaml文件里面,然后通过config.py来配置环境
选择用config.yaml也是歪打正着,之前的博客就是用的config.yaml来配置环境的,所以我第一个想到的就是这个。这个方法有一些个有点,比如易读,对非程序员友好,可以添加注释,层级分明等
比如我的配置就是:
# config.yaml
# 各题型数量
question_types:
- name: "single_choice"
count: 6
- name: "fill_blank"
count: 6
- name: "proof"
count: 7
#
difficulty:
target_average: 3
bucket_constraints:
star_1: 0.1
star_2: 0.1
star_3: 0.4
star_4: 0.2
star_5: 0.3
star_6: 0
data:
max_per_type: 500
paths:
single_choice: "../Dataset/by_type/single_choice.json"
fill_blank: "../Dataset/by_type/fill_blank.json"
proof: "../Dataset/by_type/proof.json"
这个,是不是非程序员读起来也没有任何压力啊?(笑)
九、接下来的目标分析
1. 求解器的优化
- 更灵活的约束自定义功能
- 6星的竞赛题单独处理的方案
2. 输出打印
将选出的题目,用某种方法,连同Latex一起排版在word上,并格式化输出,提供下载
3. 可视化界面
将界面制作成可视化、可交互的形式,可以增加体验感,提供更多的组卷形式
4. 手动组卷
使用检索原理,提供合适的(或者推荐的题目)给用户进行选择,手动组卷并输出
5. 相似题推荐
使用某种方法(可能是向量)来提供相似的题目推荐(可能有奇效,比如跨知识点的?有点难实现)
6. 接入AI功能
对上传的题目进行初步打标记:
- 可能需要使用特殊类型AI模型
- 可能需要数据训练微调
- 可能使用机器学习来评估题目相似度等数据
十、暂时的收官
就在走到这个地方的时候,我越写代码越觉得不对劲:感觉好像完全没有用到线性优化了啊?不就是简单的随机抽样吗?
然后我自己在脑袋里经历了一次真理问题的大讨论,并且和群里人问了一下,最后得到的结论是:
我想多了,我是说,我从一开始就想复杂了
这个简单的问题,用不着CP-SAT求解器来干活。只要简单的随机抽样就能完美解决
所以真的,我有点失望的。历经了这么多的学习和尝试,忽然发现自己从一开始就想复杂了,回过头看感觉好像之前做的都像是笑话
不过,我倒也不会真的难过,接下来我们可以来复盘一下到底发生了什么
1. 我的初心是什么?为什么当初选择了CP-SAT?
一开始,我把组卷想成一个0/1决策问题,每一道题目有两种状态:选和不选。然后基于此,在大规模的题库中,搜索同时满足“难度”“题型”“知识点”约束的可能组合,并优化全局,使得难度尽量贴近设定目标。CP-SAT就是一个能在大量复杂的约束中,完美解决最优解和可行解问题的一个工具。于是,我们一拍即合
这在理论上可行吗?太可行了。确实是可以实现的,不然我也不会有我的第一版release了
在进行了合理的优化后,系统确实可以在可行的时间限制内完成检索,达到我本来希望的目标。这很好,至少能证明我想的是没错的
2. 那么后来发生了什么?为什么忽然感觉想小丑?
一句话锐评的话,就是说:太高估自己了,以为自己在做一些高大上的事情,但是其实完全没必要那么复杂,自己就是在做一件很LOW的事情,不要自我陶醉
推进了一段时间,你会发现:
- 题型 → 字典 / 分类筛选
- 难度 → 最小余数分布+分层抽样
- 比例 → 前处理整数化
- 极端情况 → 明确规则直接排除
全部的算力,全部被手搓优化掉了。
也就是说,本来就不需要CP-SAT什么事。
3. 怎么回事?历史必然性呢?
请看我之前的初心:CP-SAT就是一个能在大量复杂的约束中,完美解决最优解和可行解问题的一个工具
注意看:在大量、复杂的约束中
那我问你,现在这个约束复杂吗?现在约束多吗?嗯?Look in my eyes!
所以,对于难度、题型、比例,本身就是简单的、重复的约束,不需要使用线性优化这种牛刀,我们手搓就能搓出来一个很不错的随机抽样
因此,这个约束,分为简单的约束和复杂的约束,两种处理方法是截然不同的。确实,我们使用OR-Tools这把牛刀可以解决,但是当你在不断地优化当中,逐渐把OR-Tools变成了衣来伸手饭来张口的角色,那我还要你干嘛!
4. 所以这就是故事的结局了?
不是的。请再次看向我们的初心:CP-SAT就是一个能在大量复杂的约束中,完美解决最优解和可行解问题的一个工具
所以。如果约束变得复杂了呢?那我们就又可以启用这个尘封的武器,来做一些高级的功能
其实我至今没有搞懂到底应该怎样来做一个干净的核心。我会好好想清楚再来做决定,不能再摇摆不定了。要知道,如果对手上的东西没有了解的话,是无论多久都会处于摇摆不定的状态的
我会整理好状态再来尝试!
十一、总结
在这篇文章中,我们以自动组卷系统为切入点,探讨了约束满足问题(CSP)在工程实践中的建模、实现与优化策略,并对求解器在离散优化中的边界进行了反思
这篇文章其实不能算是理论学习的文章,只能算上是偏工程部署的一个记录,主要分为三个部分
第一部分、介绍了 OR-Tools CP-SAT 的核心建模流程
我们梳理了从导入Python依赖、声明CP-SAT求解器、定义 0/1 决策变量到配置 Maximize/Minimize 目标函数的标准化步骤。
第二部分,对比了两种难度控制逻辑的工程实现
-
全局偏差模型:通过约束总分与目标总分之差,实现宏观难度对齐。
-
逐题偏差模型:引入中间辅助变量(Auxiliary Variables),对每道选中的题目施加绝对值约束。
第三部分,沉淀了在大规模数据下的工程优化策略
针对 CP-SAT 在万级变量下的性能表现,记录了数据预分层(Bucketizing)、定点化(Integer Scaling)以及使用 YAML 配置驱动 环境的工程方案,明确了:
OR-Tools 建模 = 逻辑的算术化表达 + 空间剪枝
如有纰漏,请批评指正
十二、结语:一篇混乱的文章
不知道看下来你觉得这个文章怎么样,不过其实我是有点难不愉快的,“就写成这样还好意思拿出去给别人看?”
内心有些自责,为什么没有在动笔第一个字的时候就想清楚整件事?为什么要在写了几千个字的时候忽然发现之前的一起都是浮云,忽然转变方向以后又发现自己转变方向这件事情是如此的草率?
这一次感觉自己不再是知识的传播者,自己变成了受困者,也自然没有资格指指点点,没有资格居高临下地规划,我只是一个很普通的学者,是一个研究的人。我的研究会失败,也会不断折返,螺旋形走自己走过的路
不过,我倒也不会气馁。这是一个很大的工程,仅凭我一个人的努力,再怎样努力都会变成打水漂。孤军奋战,既不是我想要的,也不是老师希望的,更不是工程的最优解。所以,其实我内心里一直希望有人能来和我一起探讨这个问题,但是又怕别人指责我癞蛤蟆想吃天鹅肉,更何况现实是,确实没有有一个人对我手上的东西感兴趣
那么以后怎样走?我也不知道,也许我需要先沉淀一下,多用脑子思考,练习一下基本功,然后再回来接手这个烂摊子吧?
也许这篇是一个失败的文章,但是至少我以后回来看的时候,我能知道自己之前是怎样想的,是怎样失败的,又在这个过程中学到了什么。总体来说,我还是很感谢能坚持写下来这个博客的自己的。就像是面对一个贮藏室,所有柜子都是关着的,我现在就是在把柜子一个一个打开,各种东西散落一地,我坐在地上狼狈地寻找。任谁来都会以为有一个熊孩子在搞破坏了,因为我自己都感觉非常混乱。但是,至少我开始了,至少我鼓起勇气把柜子打开了,我知道,下一次再进入这个房间的时候,应该按照怎样的顺序来找,一共有哪些柜子,哪些柜子又是没有用的或是有用的,我会更有底气
社交平台的信息是碎片化的,也不完全属于我。
相比之下,博客是:
- 可长期维护的
- 结构清晰的
- 可以慢慢演化的
也许这也是我坚持写博客来记录的初心吧,记住自己的全部经历,无论是成功的还是失败的,或者是经过了我无数次无数次重写的文章,至少能画下来我走过的路,知道我在干什么,兴许最后能全部串联在一起。
这片天,只属于我,所以磕了碰了都没关系,不会有人来指责我。如果有人真的那这些失败来说事,我就回一句:关你屁事!
def write_blog():
print("Keep writing.")
尝试一下图片块:

结语
总体来说大概就是这样,那么以后也请多多关照。
留下评论