DeepSeek LLM 本地部署与 LoRA 微调实录:从环境搭建到模型训练
请注意!这篇文章尚未完工!
Deepseek LLM 本地部署与 LoRA 微调:完整记录与踩坑
最近借到了舍友的RTX5070(顶礼膜拜),于是尝试本地部署DeepSeek-7B模型,并尝试进行LoRA微调。
这个过程非常漫长,我会尝试尽量全面记录自己踩过的坑,希望能帮助到同样初学的小伙伴。
除了工程记录,我会尝试解释大模型和LoRA微调的机制(这对我来说其实挺有挑战的,不过我会加油的),大概率会新开一个文章来写
1.系统搭建和环境准备
1.1 系统与工具
注意,本流程仅适用于NVIDIA RTX较新型号的显卡,因为只有这些型号的显卡可以使用CUDA加速
- 操作系统:Windows 11(使用 miniConda 配置虚拟环境)
- Python:推荐使用
Python 3.8+ - 硬件:RTX5070Ti
- 主要工具:
Deepseek 7B开源模型参数LoRA 微调(Low-Rank Adaptation)
1.2 环境搭建
配置虚拟Python环境
我这个舍友,电脑性能相当炸裂,但是他只拿来做文档和看电影,实在是太浪费了
鉴于系统几乎是全新的,我们先配置一下部署和训练的必备环境
首先,安装一个合适的IDE,我选择了Pycharm
对照python版本,下载 miniConda 包管理
安装后,打开Anaconda Powershell Prompt应用,新建一个虚拟环境
conda create -n deepseek_train python=3.8
conda activate deepseek_train

在Pycharm项目中使用这个虚拟环境
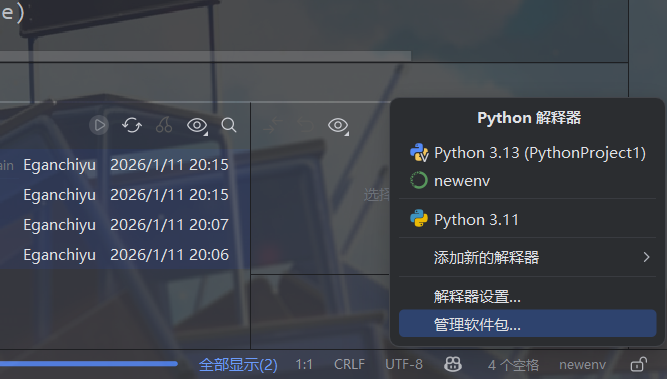
在右下角打开配置环境窗口(就是我这个newenv的位置),选择添加新的解释器-添加本地解释器-选择现有-类型Conda
然后选择安装的Conda的路径下的conda.bat文件,就可以自动读取到Conda内的虚拟环境,相对路径一般如下图所示
接下来就可以在Pycharm内使用deepseek_train内的包,并可以直接在控制台运行pip命令
配置CUDA Toolkit加速环境
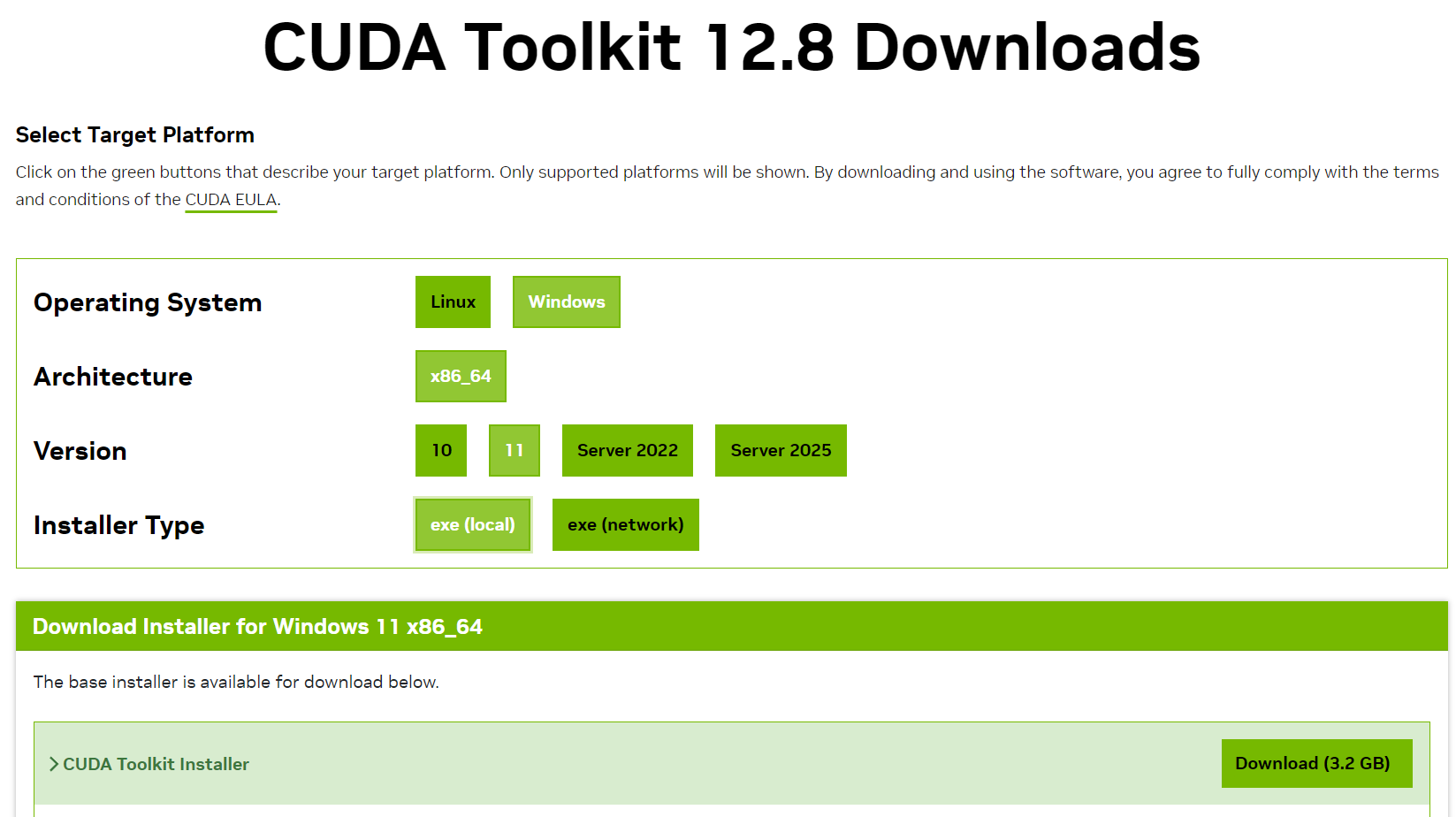
这一步非常重要!请一定要对照自己的GPU型号(只有Nvidia的RTX可以),选择对应正确的CUDA版本
对于RTX5070Ti,选择 CUDA12.8 版本
这是因为RTX 5070 Ti 采用了最新的 Blackwell 架构,其 CUDA 计算能力为 sm_120
配置Pytorch环境
在创建的虚拟环境内安装的Pytorch需要与CUDA版本对应
在官网选择自己的要求,可以生成pip的安装指令

复制指令,在虚拟环境内运行,就会自动安装完成Pytorch
至此,基础环境配置基本完成,其余模型训练所需的pip包可以在后续阶段补充安装
1.3 Deepseek模型下载与部署
在hugging face官网下载所需的模型文件(不局限于Deepseek的7B模型)
在Files and versions栏目内,下载全部的文件,并保存到同一个文件夹
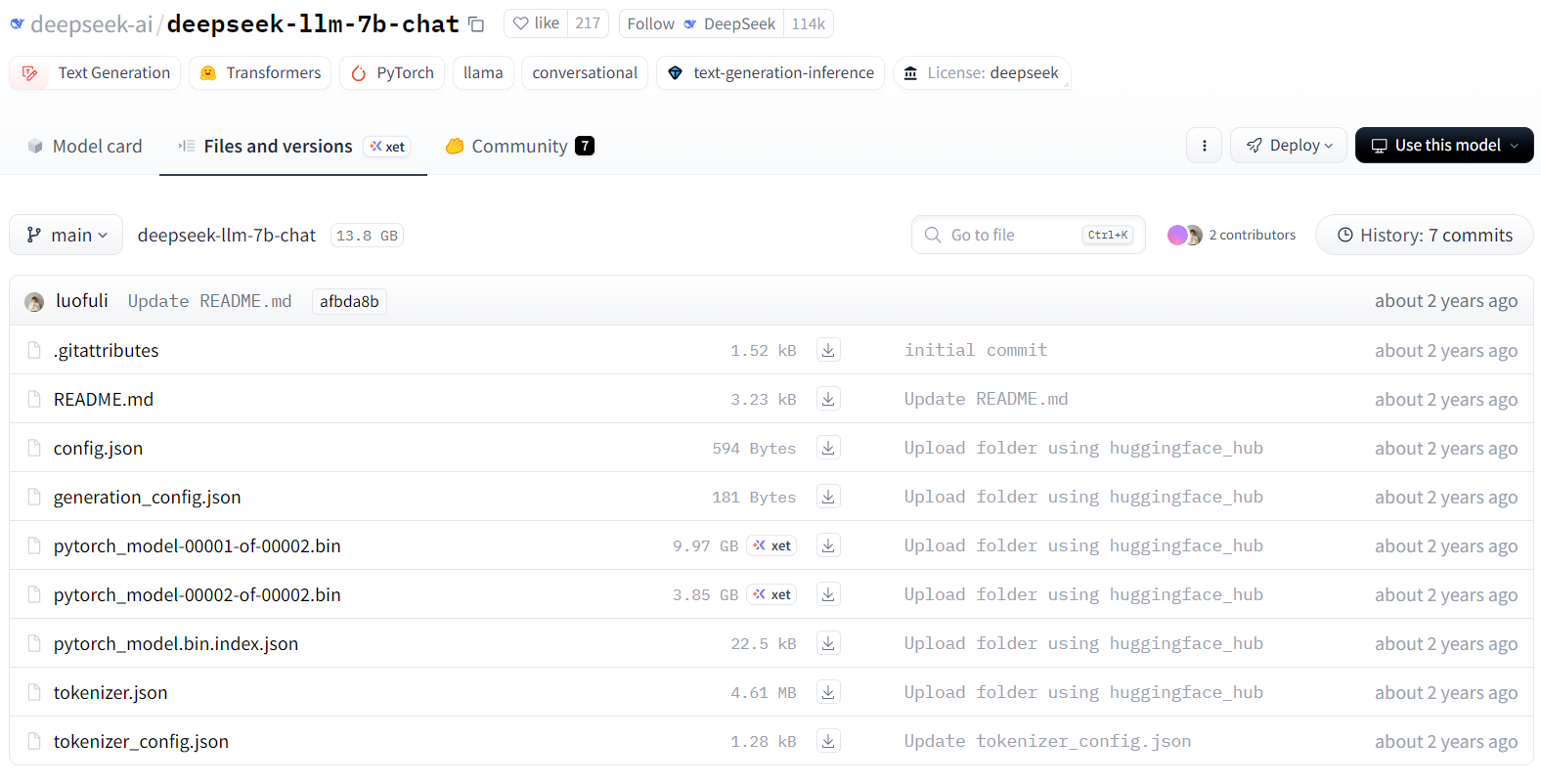
其中,最大的两个文件(pytorch_model-0000X-of-0000Y)就是模型的参数文件,是llm模型的最主要核心
其余的文件可以视为模型文件的外设和引导
将文件夹放在项目目录内,方便引用,Deepseek模型部署完毕
下载速度是一个很大的限制,这一步其实卡了我好久,轻描淡写就过去了感觉有点不太甘心(
后来发现时间是最好的解药,挂在Motrix上下了一下午终于下完了(其实就是开始慢,到后面就好多了,所以耐心一点就好了)
下面的没有修改.等我搞到一台可以实操的电脑再继续写 —
2. LoRA 微调的实现 ————–
LoRA 微调是一种通过参数化训练的方式,以低秩矩阵优化模型,尤其适用于大模型的微调,能够显著减少计算资源的消耗。
2.1 LoRA 微调前的准备
- 训练数据:确保训练数据已经预处理好,格式通常为 JSONL(每行一个样本)。
- 参数配置:根据训练目标的不同,设置微调的参数,如学习率、批次大小等。
2.2 启动训练
对于 LoRA 微调,以下是一个示例启动命令:
python train_lora.py --model_path deepseek-coder-1.3b-base --data_path train_data.jsonl --output_dir fine_tuned_model --lora_rank 8
--lora_rank 参数决定了 LoRA 微调时低秩矩阵的大小,影响训练效果和计算消耗。
2.3 错误与调试
在训练过程中,我遇到了几个常见问题,特别是在资源限制与配置不当的情况下。以下是一些解决方案:
- 显存不足:如果遇到显存不足的错误,尝试调整批次大小或使用梯度累积。
- 训练进度缓慢:如果训练过慢,可以考虑开启多线程或分布式训练。
3. 模型部署与优化
3.1 模型部署
在完成 LoRA 微调后,我们可以将模型部署到本地环境中进行测试与应用。以下是简单的部署代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("fine_tuned_model")
tokenizer = AutoTokenizer.from_pretrained("fine_tuned_model")
input_text = "Hello, how are you?"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
3.2 性能优化
对于大型语言模型,推理速度可能会较慢。为此,可以考虑以下优化策略:
- 量化:使用模型量化技术减少模型的大小和推理时间。
- 模型剪枝:通过修剪不必要的网络参数,提高推理速度。
4. 总结与反思
4.1 总结
通过这一过程,我成功地完成了 Deepseek 模型的本地部署与 LoRA 微调。微调过程虽有挑战,但通过合理配置和调试,最终获得了较好的性能。
4.2 踩坑经验
- 环境依赖问题:在某些依赖包版本不兼容时,可能导致训练失败。解决方法是更新
transformers和torch到兼容版本。 - 显存不足问题:LoRA 微调是资源密集型的,确保有足够的 GPU 支持,并合理配置训练参数。
希望这篇博客能帮助你快速完成类似的部署与微调工作。如有任何问题,欢迎留言交流。
留下评论